How No–Code RAG Unlocks the Power of Unstructured Data for GenAI
Last Published: Sep 24, 2025 |
Table Of Contents
If you’re a data engineer or an artificial intelligence (AI) practitioner involved in generative AI (GenAI) projects, you know continuous access to up-to-date information for your large language model (LLM) is integral to success. The challenge, however, is to power your LLM with the latest information in the least amount of time and return the most accurate and contextual response to the user.
In other words, for AI success, the LLMs powering them must have real-time access to continuous, diverse and numerically organized data that is:
- Current: For the most accurate responses, LLMs need access to the most updated version of the data flowing in from various sources.
- Contextual: For LLMs to return a response based on a contextual understanding of the data, the generic training data needs to be augmented with context-specific data. For example, this includes internal company data (such as customer reviews, social media pages, call center records, sales and service records, etc., generated in real-time) and industry-specific data (such as laws and regulations or competitor information).
- Numerical: LLMs require data to be in a specific format for optimal performance. It must be numerical, well-organized and indexed to enable you to retrieve accurate answers quickly. It’s important to note that LLMs cannot comprehend human language or unstructured data like images and videos. Their capabilities are limited to searching and retrieving numerical data in predetermined formats.
Additional must-have capabilities of successful GenAI models include built-in bias mitigation and regulatory compliance with data and feedback loops for continuous improvement in the LLMs response accuracy.
A better approach than constantly retraining LLMs on new data is to connect the LLM — GPT, Llama or Bert — to a source of constantly updated information that can be efficiently searched for the most relevant response. Recently, VectorDBs have emerged as the preferred way to store data that can power GenAI initiatives.
The Growing Importance of RAG In VectorDB-Powered GenAI Projects
Retrieval Augmentation Generation (RAG) is an architecture that enhances the capabilities of GenAI chat interfaces by improving their ability to retrieve and generate relevant, contextually aware responses.
Organizations building AI applications at scale depend on VectorDBs to store their data in a format optimized for highly efficient search. RAG architecture lets the LLM connect to the VectorDB and retrieve the best-fit data in the most efficient and optimal way possible.
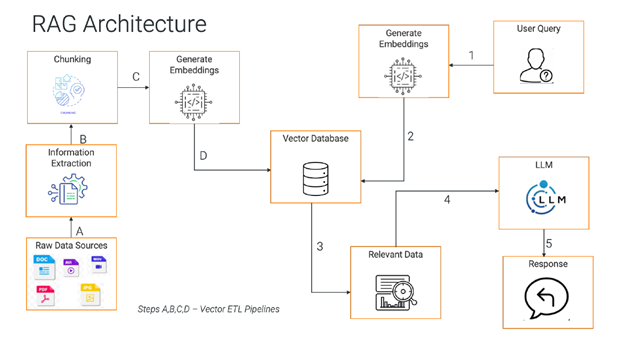
Figure 1: An overview of a RAG architecture.
The benefits of RAG include:
- Enhanced information retrieval
- Combines the strengths of retrieval systems and generative models
- Fetches relevant documents or data points efficiently from large datasets
- Improved contextual understanding
- Uses retrieved information to provide better context to generative models
- Produces more accurate and contextually relevant responses
- Scalability
- Can handle large-scale data and user interactions efficiently
- Suitable for applications with vast and diverse datasets
How RAG Unlocks the Full Potential of Unstructured Data for GenAI Use Cases
RAG architectures are important for GenAI applications if you want to go beyond generic training data sets. It’s useful for leveraging internal company-specific content, data or knowledge bases for the most contextual and specific responses while minimizing machine hallucinations, errors and biases.
As more organizations implement RAG, they recognize the critical importance of data management and the need for high-quality, reliable data to ensure successful models. Because much real-time data generated is in unstructured formats — such as call center records, social media comments, reviews and internal training documents — and human languages — made up of words, pictures and videos — it must be transformed into numerical values to be used by LLMs.
As a result, a complex set of data integration operations must be performed to build the RAG architecture. This includes:
- Data ingestion: High-speed extraction, ingestion, cleansing and enrichment of structured, semi-structured and unstructured data into high-quality business-ready data.
- Data chunking: When building LLM-related applications, chunking means breaking down large pieces of text into smaller segments. It’s a technique that helps optimize the relevance of the content we get back from a vectorDB once we use the LLM to embed content. Chunking ensures LLMs are fed high-quality data by parsing unstructured data and then calling the LLMs to generate vectors. Data can be chunked based on certain characters, words, lines or sentences, paragraphs, etc. This depends on several factors, such as:
- The use case.
- The nature of the content being indexed. For instance, long documents such as books need different chunking than shorter content like tweets or instant messages.
- The expected length and complexity of user queries, for instance, short and specific vs. long and complex queries.
- How will the retrieved results be utilized within the specific application? For instance, will they be used for semantic search, answering questions, summarization, etc
- Creating embeddings: Vector embeddings — numerical representations of text that capture the relationships and meaning of words, phrases and other data types in a way that LLMs can understand — are generated once the data is chunked. For example, imagine you want to teach a computer what a dog and a puppy are. Even though the words look different, they mean something similar.
Vector embeddings help the computer understand this similarity by representing the dog and puppy as numbers. The key differentiator comes in the way vectors capture semantic meaning. This means they can be used for relevancy or context-based search rather than solely for simple text search. - Data storage: Organizing and indexing vector embeddings into the Vector DB so the LLM can access, search and retrieve the best result in response to the user query.
These ongoing data integration processes are the key to transforming mountains of semi-structured and unstructured data from diverse internal and external sources into high-quality numerical data stored in the VectorDB, which powers the AI model.
Typically, the data integration operations to build the RAG framework are performed using hand coding and open-source libraries. However, this can be expensive, time-consuming and error-prone, all of which slow down the progress of AI initiatives. Access to AI engineering talent is another challenge further hindering growth.
No-Code: A Better Way to Build RAG Architecture
A no-code, drag-and-drop approach to building the entire RAG pipeline is more efficient, accurate and scalable than the hand-coded approach. It also eliminates the complexity of these mission-critical data management tasks. Not only does it save development effort and time in a talent-scarce market, but it also empowers data engineers to implement GenAI projects more efficiently.
Enterprise-grade, no-code drag-and-drop solutions such as Informatica Cloud Data Integration offer out-of-the-box tools and connectors to help you build your RAG ingestions and the GenAI pipeline. They also come with scalable infrastructure, allowing virtually any amount of data to be processed with optimal efficiency. This is especially useful when growing from departmental to enterprise scale, a use case where free and open-source tools are often unable to deliver.
If you’re a data engineer already using no-code data integration tools, you are at an even more significant advantage, as you can use a familiar interface to build complex GenAI use cases.
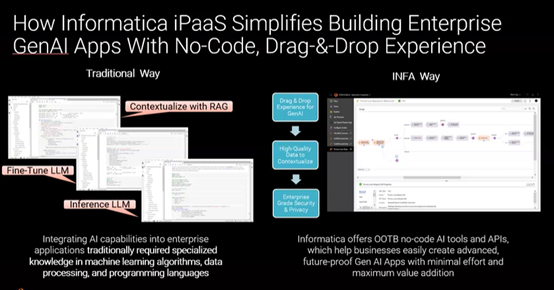
Figure 2: How Informatica iPaaS simplifies building enterprise GenAI apps with a no-code, drag-and-drop experience.
Try the No-Code Approach to Building Fast and Efficient RAG Pipelines
For companies serious about AI, a partner like Informatica is the apparent choice for GenAI data integration requirements. For business users, contextual, current and accurate responses based on RAG architecture help take the maximum advantage of unstructured data.
Sign up for a free 60-day Advanced Integration trial to get started: https://www.informatica.com/trials/advanced-integration.html