
Shortening Time to Value Using AI-Driven Data Management and Open Tables
Last Published: Sep 05, 2024 |

There's no question that there is an insatiable business demand for data and AI at present. For most companies, investment in data and analytics is now a top priority and if anything, organisations are increasing their investment because they're seeing measurable business value coming from their investment. Demand is so high that the size of the AI market is projected to grow rapidly over the next five or six years.
Although expectations are high, new trends are raising these expectations even further. For example, the emergence of AI agents is catching everyone’s attention at the moment. In fact, the internet is already awash with articles on AI agents describing how they can be used to reduce costs, improve productivity and help run your business smarter. For example, AI agents can interact with customers and employees in natural language. They can be used to automate tasks such as:
- Capturing, classifying and extracting data from content
- Entering data into applications and submitting complete transactions
- Generating content
- Generating code to clean and integrate data
- Querying and automatically analyzing data
- Taking decisions automatically
They can even automatically predict, select and sequence other AI agents to orchestrate a coordinated set of actions and dynamically change the behavior of executing business processes.
With all this hype, it's not surprising that executive expectations of data and AI are huge. They expect that data and AI will transform their business, give them speed and agility, disrupt the markets they compete in and give them a competitive advantage. But despite the fact that organisations are seeing measurable results, the maximum return on investment from AI will not happen unless there is a solid foundation of high-quality and reusable data.
However, a number of challenges are slowing progress. Many companies do not have a high- quality data foundation. Instead, they have multiple siloed analytical systems each with its own data store, point- to- point data integration and multiple copies of data. This is shown in Figure 1.
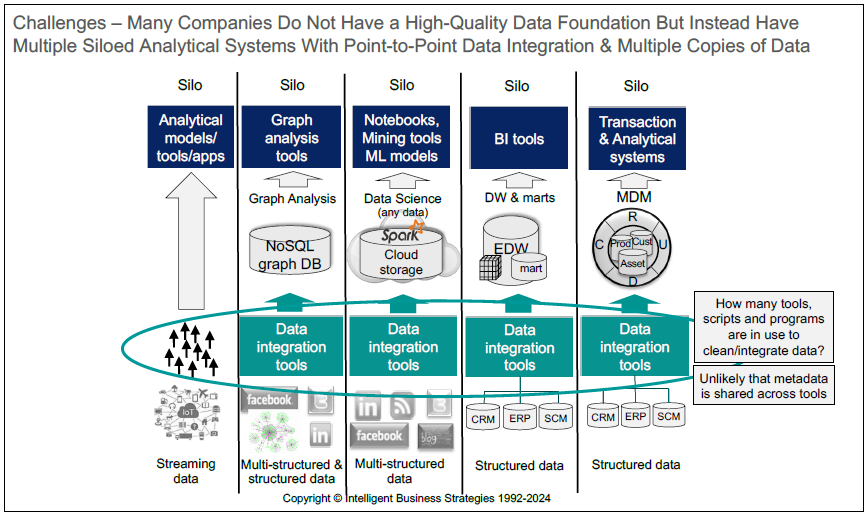
Figure 1
In addition, as the number of data sources continues to increase the number of users wanting to integrate new data with data they already have also increases to the point where central IT data engineering teams, responsible for integrating data, just can’t keep pace with business demand. In other words, IT have, through no fault of their own, become a bottleneck. Also, most companies today are dealing with the complexity of a distributed data estate where data is increasingly persisted in multiple different types of data stores on premises, in multiple clouds, in multiple software-as-a-service applications, and is also streaming in from IoT devices at the edge. As the number of data sources grows, this makes data increasingly difficult to find, manage, and integrate. Data governance is also a major challenge, with most companies still reliant on an army of administrators of different systems implementing what they hope are the same policies in each individual system to try to govern data in a consistent fashion across a distributed data estate.
Given these challenges, the question everyone wants to know the answer to is how can you overcome them so that you can shorten time to value to reap the business benefits that high-quality integrated data and AI can bring?
There are five major things that can be done to shorten time to value. These are as follows:
- Democratize data engineering
- Create data products to incrementally build a data foundation that underpins multiple analytical and AI initiatives
- Use data fabric as a common platform to help rapidly understand, manage and govern your data estate and also to enable multiple teams around the business to build high-quality, reusable data products
- Implement a modern data architecture that utilizes open table formats to share data across multiple analytical workloads and eliminate multiple analytical silos
- Use generative AI in data management to accelerate development and use
These five items help to industrialize the development of data and analytics in a similar fashion to how Henry Ford industrialized car production. What most companies want is to establish a production line for data and AI to accelerate development. Democratizing data engineering can be done by creating multiple teams of data producers around the organization that can make use of a data catalog and common data fabric to build high-quality, reusable data products that can be published in a data marketplace for consumers to find and use.
What do we mean by data products? We mean physical datasets representing core data entities in your business. For example, customers, orders, products and payments. These are examples of foundational data products that every business should have. However, I do not regard things like BI reports, dashboards, machine learning models, AI bots etc., as data products. To me, these are analytical products that are built using data from data products. Of course, we need both data and analytical products but the latter is dependent on the former.
How do you build a data and AI foundation providing timely, high quality, compliant data and analytical products on a distributed data estate? The answer is that you need data fabric and a modern data architecture.
Data fabric is a common, integrated data management software platform with built-in AI assistance, that can be used for data engineering to produce high quality, reusable data products and for data governance. An example of a data fabric data management platform is Informatica IDMC. The purpose of data fabric is to act as a common data platform for multiple domain-oriented teams of data producers to build data products that can be published in a data marketplace and made available for sharing around the enterprise in a governed and compliant manner. Data fabric also includes a data catalog to automatically discover, classify and profile data that resides in multiple underlying data stores across your distributed data estate. The data catalog provides shared metadata that can be used by multiple teams across the enterprise. This means that metadata about your business glossary, your data sources, sensitive data, data cleansing, transformation, matching and integration rules can all be shared. Metadata lineage and data governance policies etc., can also be shared.
Multiple teams can use data fabric as a common data management platform to build data products once and reuse them everywhere to support multiple analytical workloads around the enterprise, as shown in figure 2.
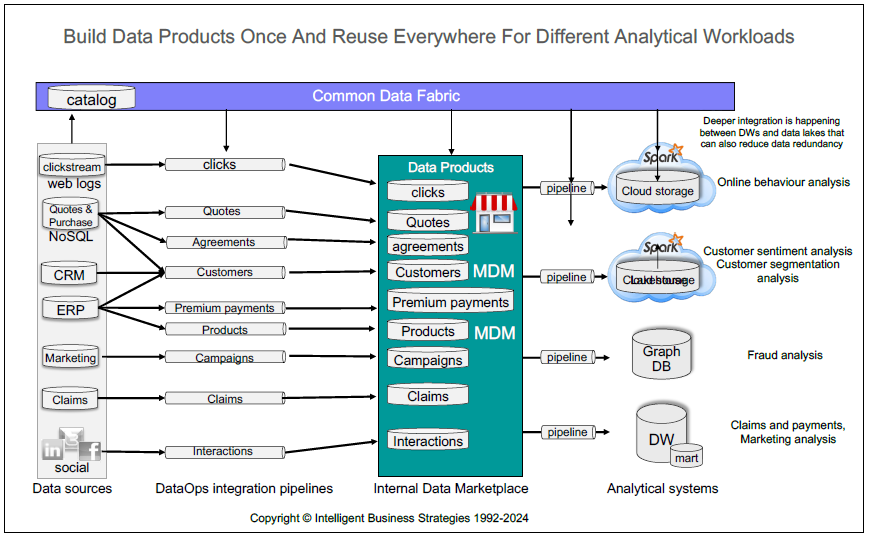
Figure 2
Furthermore, if you get this right, data products can be built once and stored in such a way that you can replace multiple siloed analytical systems with a more modern and simplified data architecture that can support multiple analytical workloads. The secret to doing this is the rapid adoption of open table formats such as Apache Iceberg, Linux Foundation Delta Lake and Apache Hudi. In the last year, we've seen almost every major analytical data warehouse database management system (DBMS) vendor announce support for open tables in addition to their own proprietary tables. This means that data stored in open tables such as Apache Iceberg tables can be shared, directly updated and accessed from a Data Warehouse DBMS using SQL and also by other engines like Flink, Spark and Presto running other analytical workloads. This has resulted in Data Warehouses and Lakehouses morphing into one as opposed to being separate platforms.
But it is more than that. The impact of open table formats has been considerable because they support ACID properties, which guarantee the transactional integrity of your data. In addition, open tables support schema change on immutable files, and time travel for historical queries. This means that high quality data products can be created and stored in open tables that guarantee consistency and data integrity. These data products can then be published in a data marketplace and made available for access by data consumers who can use that data to build BI reports, predictive and prescriptive ML models and AI agents. No copying of data is required as was the case in Figure 1.
The result is a new modern data architecture for converged analytical workloads with access to shared data products stored in open tables from multiple engines supporting different analytical workloads. This is shown in figure 3.
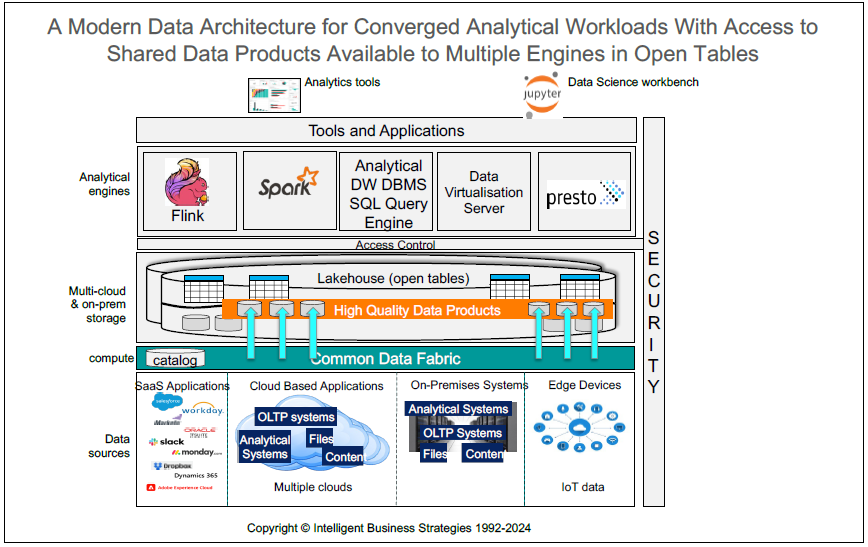
Figure 3
Figure 3 is very different from Figure 1. As you can see, we have replaced multiple siloed analytical systems with a new modern data architecture that supports the incremental building of data products by multiple teams using Data Fabric - a common data management platform. Note that the data products created and stored in open tables do not all have to be collocated. They can be stored across multiple different clouds and on-premises. However, all are accessible from multiple engines running different analytical workloads e.g. Flink with streaming analytics, Spark for data science and data warehouse queries via the data warehouse DBMS query engine.
Last but not least is the role of generative AI in data management. This has emerged in almost every aspect of data management including data catalogs, data modeling, data engineering, data governance, data marketplace and more. A major benefit of generative AI in data management is that it provides significant productivity gains. For example, generative AI-powered conversational data search and AI-assisted metadata curation in data catalogs help data producers quickly find and curate the data they need to create new data products. Also, generative AI makes it possible to use natural language prompts to automatically generate code to validate, clean and integrate data and generate data governance policies to govern data quality, data privacy, data access security, data sharing etc.
The use of a data catalog with Generative AI is very important. For example, a data catalog contains a metadata knowledge graph about all your data and data relationships distributed across your data estate. This metadata knowledge graph can be used as a data source in Retrieval Augmented Generation (RAG) to convert the metadata in the knowledge graph into vectors so that large language models know about your data.
Generative AI can also be used in data catalogs to automatically generate descriptions for the data assets discovered during catalog scans of data stores in your data estate.
Once this has been done it is also possible to use Generative AI prompt-based data engineering to automatically generate data integration pipelines that clean and engineer source data to produce reusable data products. This is a major productivity boost that makes it possible for lesser-skilled citizen data engineers to develop pipelines which is required when democratizing data engineering. But it is not until you look at what’s possible today in AI-assisted end-to-end data management that you realize the productivity boost. AI-infused Data Fabric platforms can automatically discover, classify and profile source data across a distributed data estate, automatically map those disparate data assets to common business terms in a business glossary to help understand data meaning and automatically identify sensitive data. Generative AI can also be used to automatically generate descriptions to enrich data asset metadata curation and automatically generate data engineering pipelines from natural language prompts to integrate that data to create data products. All of this together significantly shortens the time to value.
In conclusion, companies need to address a number of challenges. This includes the complexity of a distributed data estate, siloed analytical systems and fractured development of data and AI with point-to-point data integration. Also, as data sources grow, data engineering needs to be democratized to keep pace with business demand. Using AI-assisted Data Fabric as a common platform hides data complexity and simplifies governance of a hybrid multi-cloud distributed data estate. It also enables multiple teams to share metadata and incrementally develop reusable data products using generative AI to accelerate development. The adoption of open table formats by analytical relational DBMS vendors is causing the data warehouse and lakehouse to morph into one. Also, it enables siloed analytical systems to be replaced by a modern data architecture that can share data products across multiple analytical workloads such as traditional BI, ML model development, streaming analytics and graph analysis in a multi-cloud environment. It also means that a prompt-based user interface can be used to combine multiple types of analytics (e.g. SQL and ML, ML and Graph) in a single query to create totally new insights for competitive advantage.
I hope you have found this useful. If you are interested in more detail, I will be presenting on this topic at the Informatica Data and AI Architecture Summit 2024. You can register for this event here: https://now.informatica.com/ai-architecture-summit2024.html?Source=Mikeferguson
Mike Ferguson is the CEO of Intelligent Business Strategies. As an independent analyst and consultant, he specializes in data management and analytics. Formerly he was the co-founder of Codd and Date – the inventors of the Relational Model and Chief Architect at Teradata. He is also Conference Chairman of Big Data LDN, the largest Data and Analytics conference in Europe and a member of the CDMC Executive Advisory Board.








